

Introduction:
Video data has become a valuable resource for training machine learning models across various domains. From object recognition to activity detection, video data provides rich and dynamic information that can significantly enhance the accuracy and performance of machine learning algorithms. In this blog post, we will explore tips for maximising the utility of Video Data Collection to achieve optimal machine learning outcomes.
Define Clear Objectives:
Before starting the video data collection process, it is crucial to define clear objectives for your machine learning project. Determine the specific tasks or applications you want to address with the collected video data. Whether it's object detection, action recognition, or video summarization, clarifying your objectives will guide the collection process and ensure the relevance of the gathered data.
Consider Data Diversity:
To build robust machine learning models, ensure the collected video data represents diverse scenarios, environments, and demographics relevant to your application. Consider factors such as lighting conditions, camera angles, backgrounds, and variations in object appearances. A diverse dataset enables your models to generalise better and perform well in real-world situations.
Quality Matters:
Ensure the quality of your video data is high. Poor quality videos can introduce noise and affect the performance of machine learning algorithms. Use high-resolution cameras and ensure sufficient lighting conditions for optimal Image Data Collection quality. Regularly monitor and assess the collected data for any issues such as blurriness, artefacts, or sensor noise that may compromise the accuracy of your models.
Annotate and Label Data:
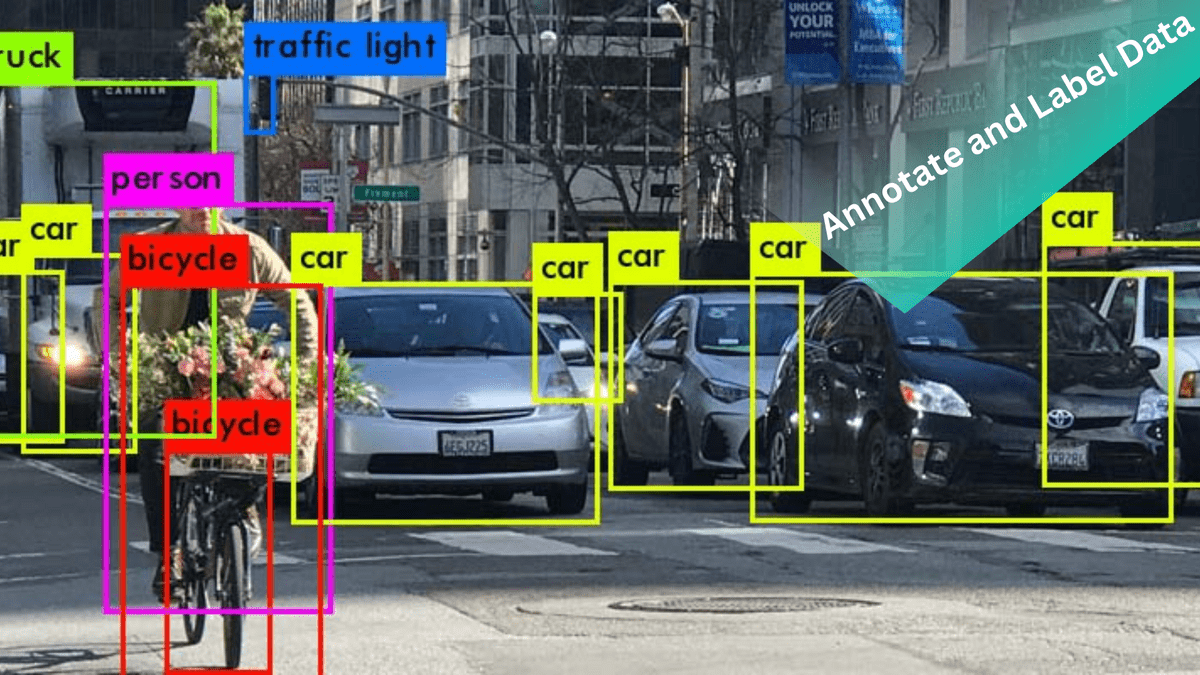
Annotating and labelling video data is a crucial step in preparing it for machine learning. Define clear annotation guidelines and annotate the relevant objects, actions, or events within the videos. Frame-level annotations can be used to indicate the presence or absence of specific objects or actions. Timestamped annotations provide temporal context and enable the models to understand the sequence of events.
Leverage Spatial and Temporal Context:
Videos offer both spatial and temporal information. Utilise this context to enhance the utility of your video data. Spatial context involves capturing relationships between objects in a frame, such as object interactions or relative positions. Temporal context involves capturing the evolution of events over time, such as motion patterns or activity transitions. Leveraging both spatial and temporal context can significantly improve the performance of machine learning models.
Consider Multi-Modal Data:
Incorporating multi-modal data can further enrich your video dataset. For example, pairing video data with accompanying audio or sensor data can provide additional cues and context. Audio can help identify specific sounds or speech, while sensor data can capture environmental conditions or motion-related information. Integrating multi-modal data enables a more comprehensive understanding of the video content.
Data Augmentation Techniques:
Data augmentation techniques can help increase the size and diversity of your video dataset. Techniques such as flipping, scaling, rotation, or adding noise can create variations of the original video data. Data augmentation can reduce overfitting, improve model generalisation, and enhance the robustness of your machine learning models.
Continuous Evaluation and Iterative Improvement:
Regularly evaluate the performance of your machine learning models and iterate on the video data collection process. Collect feedback from model outputs, analyse performance metrics, and gather insights from domain experts. Use this feedback to identify areas of improvement, refine the data collection strategy, and continuously enhance the quality and utility of your video dataset.
Conclusion:
Maximising the utility of video data collection is essential for achieving optimal machine learning outcomes. By defining clear objectives, considering data diversity, ensuring data quality, annotating and labelling data accurately, leveraging spatial and temporal context, incorporating multi-modal data, employing data augmentation techniques, and embracing continuous evaluation, companies can build robust machine learning models that excel in video analysis tasks. Collecting high-quality, diverse video data sets the foundation for successful machine learning applications across various domains.
How GTS.AI Can Help You?
At Globose Technology Solutions Pvt Ltd (GTS), we understand the importance of high-quality video data collection and offer comprehensive solutions to fuel the success of your multimodal learning projects. By leveraging the power of video data and integrating it with audio and text, you can unlock the full potential of AI and pave the way for innovative and impactful AI applications.