

Introduction:
Text-to-speech (TTS) technology has made significant advancements in recent years, thanks to the power of machine learning (ML). One of the critical factors contributing to the success of TTS models is the availability of high-quality and diverse datasets. In this blog post, we will delve into the importance of benchmarking and evaluating Text-To-Speech Datasets in ML applications. By understanding the benchmarking process and its significance, we can ensure the development of robust TTS models for various applications.
Why Text-to-Speech Dataset Benchmarking Matters:
Benchmarking TTS datasets involves evaluating their quality, diversity, and suitability for training ML models. Here are some reasons why benchmarking is crucial:
- Performance Comparison: Benchmarking enables researchers and developers to compare the performance of different TTS datasets. By evaluating multiple datasets against a standardised set of metrics, such as speech naturalness, prosody, and pronunciation accuracy, we can identify the strengths and weaknesses of each dataset and make informed decisions regarding their usage in ML models.
- Model Development and Improvement: Benchmarking helps drive the development and improvement of TTS models. By using high-quality benchmark datasets, researchers can assess the performance of their TTS models objectively and identify areas for enhancement. It allows for iterative refinement of models and facilitates the development of state-of-the-art TTS systems.
- Generalisation and Real-World Applicability: A robust TTS model should be capable of generalising well to various text inputs and producing natural and coherent speech output. Benchmarking datasets that cover a wide range of linguistic variations, languages, and speaking styles enables the evaluation of a model's generalisation abilities and its applicability to real-world scenarios.
The Benchmarking Process:
The benchmarking process for TTS datasets typically involves the following steps:
- Dataset Selection: Selecting appropriate benchmark datasets is crucial. Datasets should encompass a variety of speech characteristics, languages, and Text Data Collection types. Well-known TTS datasets like LJSpeech, LibriTTS, and Common Voice have been widely used for benchmarking.
- Evaluation Metrics: Define a set of evaluation metrics to assess the performance of TTS models trained on benchmark datasets. Metrics can include speech naturalness, intelligibility, pronunciation accuracy, and prosody. It is important to choose metrics that align with the specific goals and requirements of the TTS application.
- Model Training and Evaluation: Train TTS models on the benchmark dataset using state-of-the-art ML techniques such as deep learning. Evaluate the trained models using the defined evaluation metrics. This process helps identify areas for improvement and compare the performance of different TTS models trained on the same benchmark dataset.
- Iterative Refinement: Based on the evaluation results, iterate and refine the TTS models to enhance their performance. This may involve adjusting the architecture, incorporating additional training data, or fine-tuning hyperparameters. Benchmarking facilitates this iterative refinement process by providing a standardised evaluation framework.
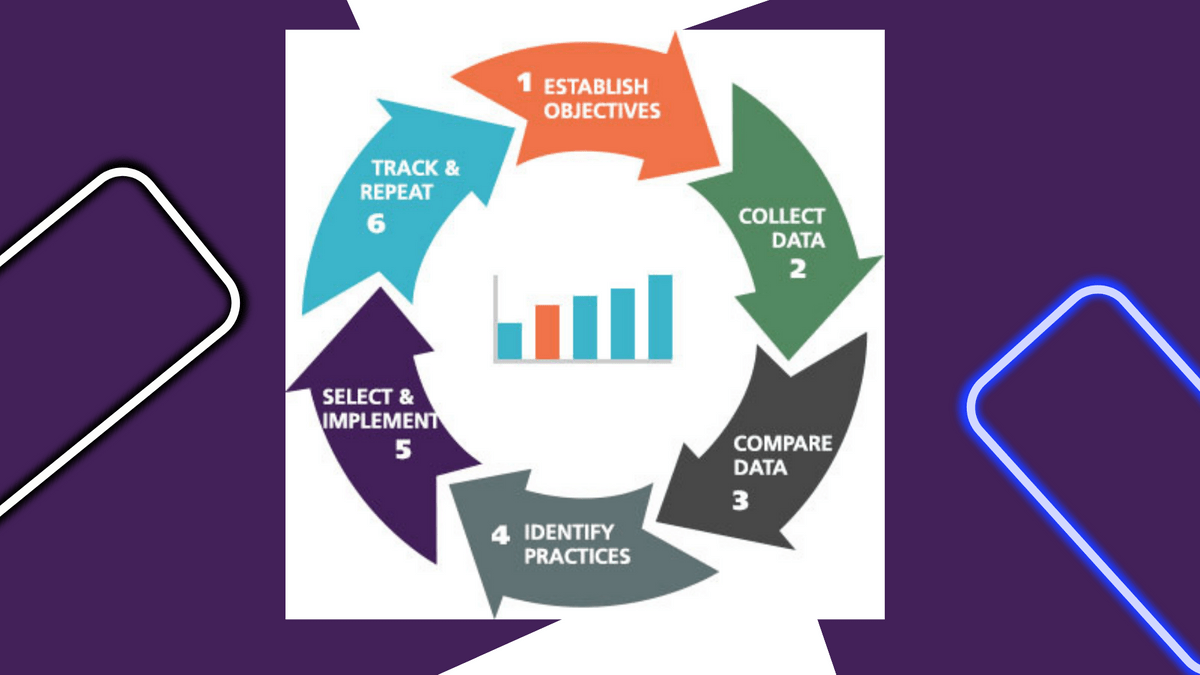
Conclusion:
Benchmarking and evaluation of text-to-speech datasets are essential for developing and improving ML-based TTS systems. By benchmarking datasets, researchers and developers can objectively compare performance, identify strengths and weaknesses, and drive innovation in the field. The benchmarking process enables the selection of high-quality datasets, ensures generalisation to diverse text inputs, and promotes the development of robust and natural-sounding TTS models. As TTS technology continues to advance, the benchmarking and evaluation of datasets will play a critical role in pushing the boundaries of what is possible and delivering high-quality speech synthesis for a range of applications, including voice assistants, audiobooks, accessibility tools, and more.
How GTS.AI Can Help You?
Globose Technology Solutions Pvt Ltd (GTS) emerges as a maestro in crafting these datasets, infusing AI models with the essence of spoken language. As AI continues to push boundaries, GTS's contribution in enabling machines to converse, express, and connect is profound. The era of talking machines is here, and with GTS's expertise, these machines are not just talking; they are conversing in the vibrant tones of humanity. Through careful curation and innovative strategies, GTS is giving voice to the silent world of technology, painting a future where machines speak the language of the heart. Text-to-speech datasets are the magical spell that brings machines to life, enabling them to communicate in the rich tapestry of human speech.